GPT 5.2 vs Claude Opus 4.5: Which AI Coding Model Fits Your Workflow Best?
A clear and practical comparison of GPT 5.2 vs Claude Opus 4.5 for real-world coding tasks, covering benchmarks, developer experience, and when to choose each model.

GPT 5.2 vs Claude Opus 4.5: Which AI Coding Model Fits Your Workflow Best?
The AI coding world reached a new peak at the end of 2025, and one comparison kept coming up in
developer communities again and again: GPT 5.2 vs Claude Opus 4.5.
If you write code for a living, this isn’t just another model-versus-model debate — it’s about choosing
the assistant that actually fits your daily workflow.
In this post, I’ll walk through GPT 5.2 vs Claude Opus 4.5 in a simple, readable way, based strictly on the provided benchmark data and real-world observations. No hype, no rewritten numbers — just practical insights.
The Context: Why GPT 5.2 vs Claude Opus 4.5 Matters
December 2025 was intense for AI developers. Within three weeks:
- Claude Opus 4.5 launched on November 24, 2025
- GPT 5.2 followed on December 11, 2025
- Competition escalated fast, especially around coding performance
Both models quickly became the top choices for serious software engineering tasks. The GPT 5.2 vs Claude Opus 4.5 debate exists because both are excellent, but they shine in different ways.
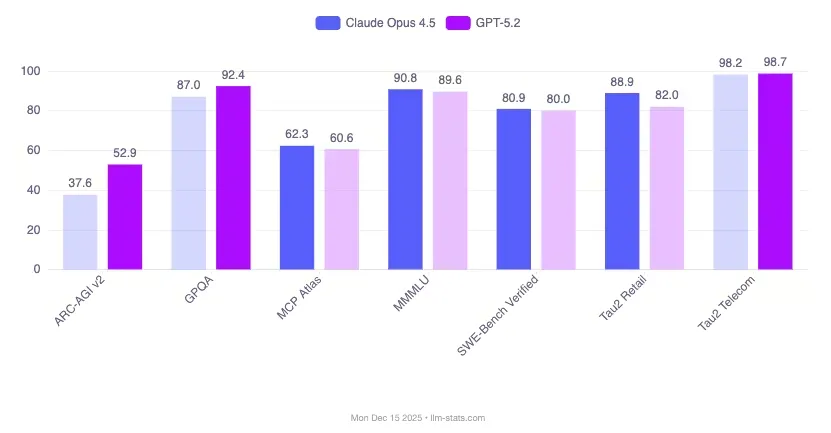
Understanding the Benchmarks (In Plain English)
Before comparing GPT 5.2 and Claude Opus 4.5, it helps to know what the benchmarks actually test.
SWE-bench (Real Bugs, Real Code)
SWE-bench uses real GitHub issues. The model must fix actual bugs or implement real features.
- Claude Opus 4.5: 80.9% on SWE-bench Verified
- GPT 5.2: 80.0% on SWE-bench Verified
This tiny gap shows how close GPT 5.2 vs Claude Opus 4.5 really is when it comes to practical bug fixing.
Terminal-bench (Command Line Skills)
This benchmark focuses on shell commands, file systems, and terminal workflows.
- Claude Opus 4.5: 59.3%
- GPT 5.2: ~47.6%
For DevOps-heavy or backend workflows, Claude Opus 4.5 clearly feels more “at home” in the terminal.
Math & Reasoning (AIME 2025)
This matters more than it sounds — strong math often means better algorithmic reasoning.
- GPT 5.2: 100% (without tools)
- Claude Opus 4.5: ~93%
This is one of the biggest differentiators in the GPT 5.2 vs Claude Opus 4.5 comparison.
GPT 5.2: Where It Truly Excels
GPT 5.2 is built around deep reasoning and large-scale understanding.
Why developers like GPT 5.2:
- Perfect AIME 2025 score shows elite reasoning ability
- 400k token context window, with near-perfect accuracy at 256k
- Strong at frontend, UI, and complex architecture
- Tends to ask clarifying questions before coding
- Produces robust error handling by default
GPT 5.2 shines when you:
- Work with large or legacy codebases
- Need multi-file refactors
- Build complex UI systems
- Solve algorithm-heavy or logic-intensive problems
In many workflows, GPT 5.2 feels like a senior engineer who wants to fully understand the system before touching the code.
Claude Opus 4.5: Precision and Efficiency
Claude Opus 4.5 focuses on accuracy, speed, and clean execution.
Where Claude Opus 4.5 stands out:
- Best SWE-bench Verified score at 80.9%
- Strong terminal and DevOps performance
- More concise, token-efficient outputs
- Excellent at following instructions precisely
Claude Opus 4.5 often feels faster and more direct. For teams that value:
- Backend reliability
- Infrastructure automation
- Shell-heavy workflows
Claude Opus 4.5 is extremely compelling in the GPT 5.2 vs Claude Opus 4.5 decision.
Developer Experience: Benchmarks Aren’t Everything
One important lesson from the GPT 5.2 vs Claude Opus 4.5 debate is this:
The “better” model depends on how you code.
Many advanced teams actually use both:
- GPT 5.2 for reasoning, planning, UI, and large refactors
- Claude Opus 4.5 for precise fixes, terminal tasks, and CI-related work
Benchmarks show capability — real workflows decide value.
Try GPT 5.2 and Claude Opus 4.5 for free on MixHub AI.

Final Thoughts: GPT 5.2 vs Claude Opus 4.5
The truth is simple:
- GPT 5.2 is a reasoning powerhouse with massive context awareness
- Claude Opus 4.5 is a precision-focused coding specialist
The GPT 5.2 vs Claude Opus 4.5 choice isn’t about which model wins — it’s about which one fits your development style.
If your work demands deep understanding and long-term context, GPT 5.2 is hard to beat.
If accuracy, speed, and terminal mastery matter more, Claude Opus 4.5 is a fantastic choice.
In late 2025, developers didn’t get one winner — they got options. And that’s a win for everyone.